From Fighting Infrastructure to Building Products with BigQuery

Get Unlimited Access to IPinfo Lite
Start using accurate IP data for cybersecurity, compliance, and personalization—no limits, no cost.
Sign up for freeAt IPinfo, we're building the data infrastructure that powers fraud prevention, cybersecurity, and compliance for developers and enterprises worldwide. Behind every API response our customers rely on is a constant flow of data processing: ingesting billions of IP data points from hundreds of different sources, enriching them with context, and keeping everything fresh and accurate.
That behind-the-scenes work became our bottleneck. The internal queries our engineers ran to build datasets, test hypotheses, and develop new features were becoming impossibly slow. A job that once took an hour stretched to ten hours. Our team spent more time optimizing database queries than actually building products.
Then we ran an experiment: we took our most painful internal query (a six-hour data processing job we'd optimized endlessly) and ran it in Google BigQuery. One minute later, it was done. Cost? A few dollars. That moment changed everything.
The PostgreSQL Wall
In our early days, PostgreSQL handled our workload. It was reliable, well-understood, and worked beautifully… until it didn't.
As our data collection efforts scaled and our datasets grew into the billions of rows, query times stretched from reasonable to painful. Beyond slowing development, this created an operational strain; data jobs had to be scheduled overnight, delaying feature rollouts and experimentation cycles.
We brought in world-class PostgreSQL expertise. Our consultant helped us squeeze more performance out of the system, but we kept hitting the same fundamental barrier: relational databases weren't designed for the scale and query patterns we needed.
"We were hiring the world's leading experts just to keep the lights on," says Ben Dowling, IPinfo's founder and co-CEO. "And even then, we kept running into new performance walls. Every optimization bought us a few months, then we'd hit another limit."
We explored Amazon Redshift, but its fixed monthly pricing model meant paying for capacity whether we used it or not. For a company that runs intensive processing jobs intermittently throughout the day, that didn't make financial sense.
We needed something different. We needed to stop fighting our infrastructure and start building again.
The BigQuery Breakthrough
BigQuery's value proposition was compelling from day one: pay only for what you query, with massive performance gains and minimal migration friction.
As mentioned earlier, that first one-minute BigQuery job was the moment everything changed for us. At the time, we didn’t expect a miracle; we simply wanted to test whether BigQuery could handle one of our biggest internal queries better than PostgreSQL.
What happened next surprised everyone. Result: one minute. Cost: a couple of dollars. No massive rewrite. No infrastructure overhaul. Just better technology doing what it was built to do. What we thought would be a small experiment turned into a proof point that redefined how we handle data.
But the real breakthrough wasn’t just the speed. It was discovering an entirely different way of working:
- True pay-as-you-go pricing. No idle capacity costs. No fixed monthly fees for resources we weren't using. We only paid when queries actually ran.
- Minimal migration effort. Many of our PostgreSQL queries worked in BigQuery with little or no modification. What we expected to take weeks often took less than an hour.
- Freedom to focus forward. Instead of endless database tuning, our engineers could focus on extracting insights and building products.
A Migration Without Disruption
Rather than a risky "big bang" migration, we took a gradual, pragmatic approach that proved remarkably smooth.
We started by moving our most time-critical jobs (the ones causing the most pain). These were often the complex aggregations and joins across massive datasets that overwhelmed PostgreSQL. In BigQuery, they just ran.
For new projects, the decision was easy: build on BigQuery from day one. Legacy workloads stayed on PostgreSQL until it made sense to migrate them. There was no pressure, no arbitrary deadline.
We developed a hybrid workflow that worked beautifully: run heavy processing jobs in BigQuery, then sync the results back into PostgreSQL when needed. This let us get immediate benefits without disrupting existing systems.
Over roughly a year, the majority of IPinfo's data processing naturally migrated to BigQuery. No big rupture. No system downtime. Just continuous improvement.
"The migration was surprisingly organic," Dowling notes. "We'd identify a bottleneck, move it to BigQuery, see immediate results, and move on. For specific queries, it would sometimes just work, or need a few tweaks. There was no need to make a massive commitment upfront. We just proved it out incrementally."
How BigQuery Powers IPinfo Today
Today, BigQuery is the backbone of IPinfo's data infrastructure, enabling several critical capabilities:
Massive-scale ETL processing. We ingest, enrich, and transform billions of IP data points daily. Jobs that would take days in PostgreSQL now complete in minutes, meaning our customers get fresher, more accurate data.
Rapid experimentation and development. Engineers can test new queries and validate hypotheses in real-time rather than waiting hours for results. This acceleration compounds: faster iteration means better products, delivered sooner.
Direct customer value. The performance gains aren't just internal efficiency wins. Faster processing means we can offer more real-time IP enrichment, more frequent data updates, and more sophisticated analysis to our customers. Security teams get threat intelligence faster. Developers get API responses with richer context. Enterprises get more granular compliance data.
Lean operations at scale. Perhaps most critically, BigQuery has allowed us to scale our data operations without proportionally scaling our team. We've stayed efficient and agile, focusing our engineering talent on innovation rather than infrastructure management.
Results: Speed, Efficiency, and Business Impact
The transformation is visible in our infrastructure metrics. Since migrating to BigQuery, our data operations have scaled dramatically:
Total Data Stored in BigQuery Over Time
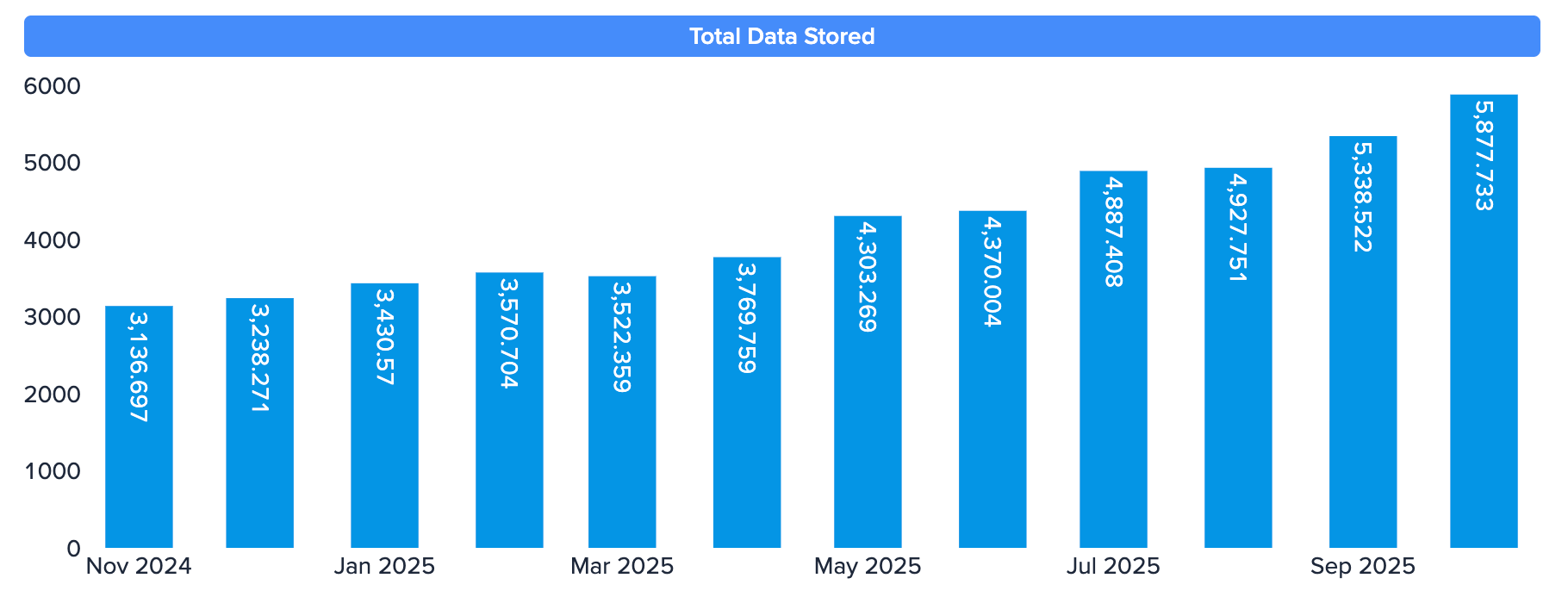
Caption: IPinfo's data storage in BigQuery has grown consistently as we've expanded our data collection, with BigQuery seamlessly handling the scale.
Data Processed Per Month
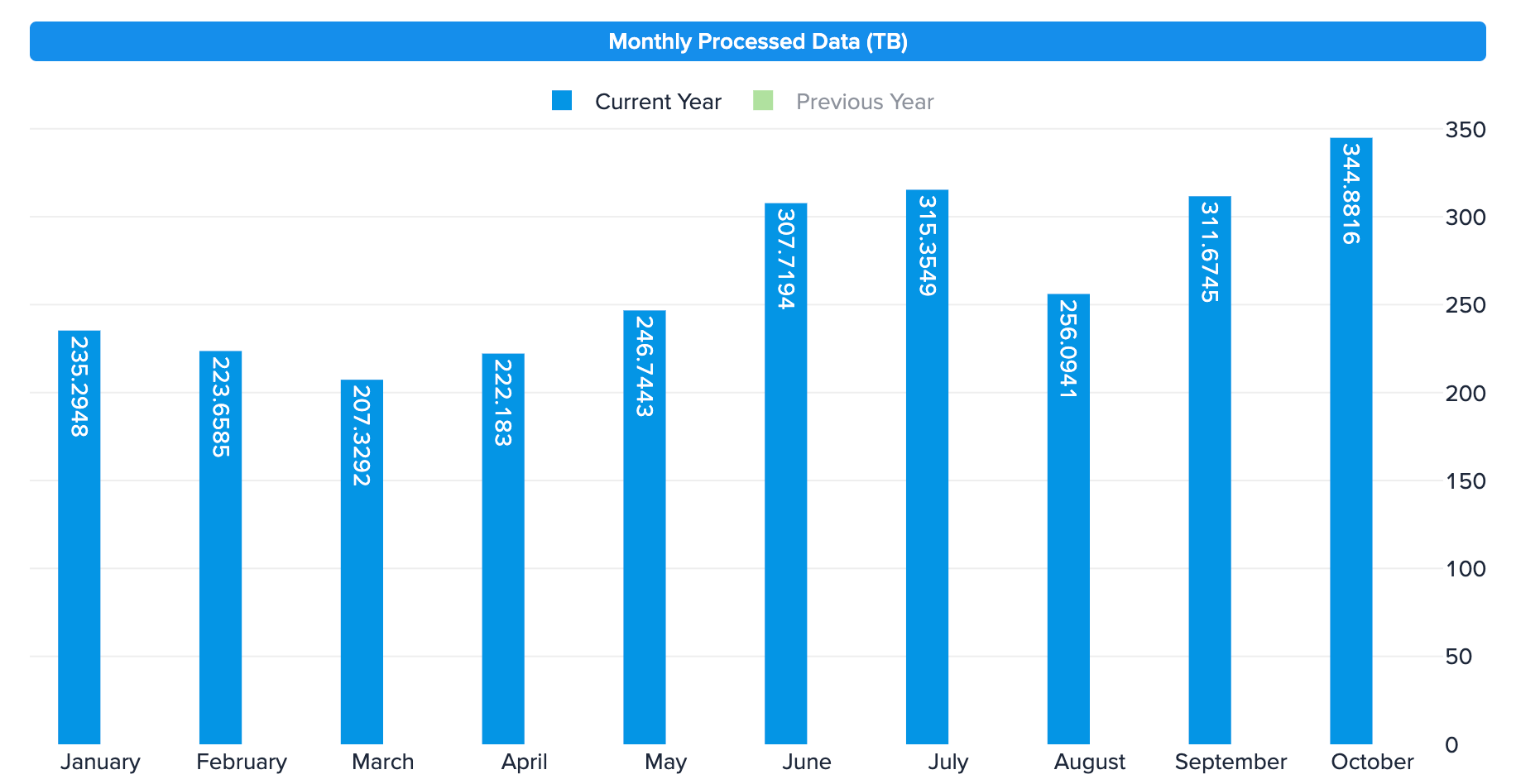
Caption: Monthly data processing volume shows how BigQuery handles massive ETL workloads that would have been impractical on PostgreSQL.
BigQuery Compute Usage Patterns
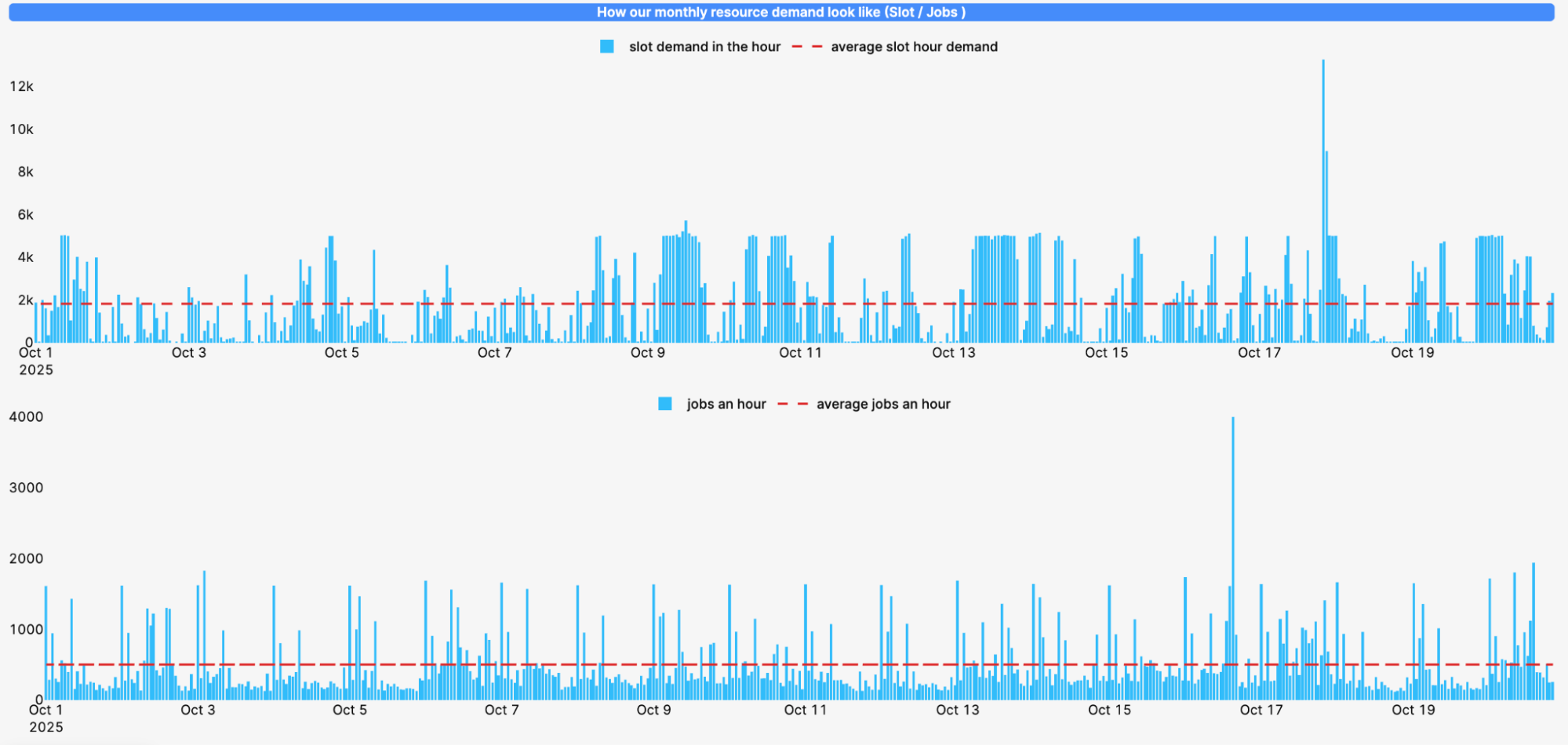
Caption: Spiky compute usage demonstrates BigQuery's pay-as-you-go advantage. We only pay when actively processing, not for idle capacity.
The key metrics tell the story:
- Query performance: Jobs that took 6+ hours now complete in 1 minute
- Data scale: ~5.9 PB stored and growing, with ~345 TB processed monthly.
- Cost efficiency: Pay only for queries run, typically just a few dollars per job with no idle capacity costs
- Engineering productivity: Team focus shifted from database optimization to product development
- Time to market: New data products ship faster with rapid query iteration
- Operational leverage: Scale achieved without proportional headcount growth
In less than a year, IPinfo’s BigQuery footprint nearly doubled, from 3.1 PB to 5.9 PB of data stored, while monthly processing grew 47% to ~345 TB. BigQuery’s elastic compute capacity absorbed this growth effortlessly, enabling IPinfo to maintain real-time enrichment performance at scale.
But the real impact goes beyond metrics. BigQuery fundamentally changed what's possible for IPinfo.
"If it wasn't for BigQuery, we'd be a much bigger company with a much bigger team just to do what we do today," Dowling reflects. "We'd be slower, more expensive, and less focused on our customers. Instead, BigQuery handles the heavy lifting, and we stay lean and focused on delivering the best IP data in the industry."
The Unoptimized Query Advantage
There's another often-overlooked benefit: BigQuery performs well even with unoptimized queries.
In the PostgreSQL days, an unoptimized query could overwhelm the entire system. Engineers had to think carefully about query structure, indexes, and execution plans before running anything significant. It was defensive, cautious work.
With BigQuery, you can run a rough first-pass query and still get reasonable performance. This changes how teams work. It enables exploration, experimentation, and rapid prototyping without the fear of taking down production systems.
"We still optimize queries in BigQuery," Dowling notes, "but it's not urgent. It's not existential. We can optimize after we've proven value, not before."
From Internal Tool to Customer Product
BigQuery worked so well for us internally that we knew our customers would benefit from the same advantages. We became the first IP data provider to offer native BigQuery integration.
Today, our customers can access IPinfo's datasets directly within BigQuery through Google Cloud Marketplace. Instead of making API calls or downloading files, they can enrich their data with IP intelligence using SQL queries, right where their data already lives.
The benefits we experienced internally (speed, cost efficiency, and scalability) now extend to our customers. Teams using BigQuery can join our IP data with their existing tables in seconds, running complex analyses that would be impractical with traditional API approaches. We've since expanded our BigQuery offerings with additional datasets, making it even easier for BigQuery users to leverage IP intelligence.
For developers and data teams already working in the Google Cloud ecosystem, our native BigQuery integration means one less API to manage, no data export pipelines to maintain, and the ability to work entirely within their existing infrastructure.
Looking Forward
BigQuery isn't just solving today's problems for IPinfo. It's enabling tomorrow's opportunities.
As we continue expanding our data collection and enrichment capabilities, we're confident BigQuery will scale with us. We're building more sophisticated, customer-facing data products directly on BigQuery's infrastructure, knowing the foundation is solid.
The lesson from IPinfo's experience is clear: the right data infrastructure doesn't just prevent problems, it unlocks possibilities. By choosing BigQuery, we've transformed our data platform from a constraint into a competitive advantage.
Share this article
About the author

As the product marketing manager, Fernanda helps customers better understand how IPinfo products can serve their needs.